

re you a content creator or a blog author who generates unique, high-quality content for a living? Have you noticed that generative AI platforms like OpenAI or CCBot use your content to train their algorithms without your consent? Don’t worry! You can block these AI crawlers from accessing your website or blog by using the robots.txt file.

What is a robots.txt file?
A robots.txt is nothing but a text file instructs robots, such as search engine robots, how to crawl and index pages on their website. You can block/allow good or bad bots that follow your robots.txt file. The syntax is as follows to block a single bot using a user-agent:
user-agent: {BOT-NAME-HERE}
disallow: /
Here is how to allow specific bots to crawl your website using a user-agent:
User-agent: {BOT-NAME-HERE}
Allow: /
Where to place your robots.txt file?
Upload the file to your website’s root folder. So that URL will look like:
https://example.com/robots.txt https://blog.example.com/robots.txt
See the following resources about robots.txt for more info:
- Introduction to robots.txt from Google.
- What is robots.txt? | How a robots.txt file works from Cloudflare.
How to block AI crawlers bots using the robots.txt file
The syntax is the same:
user-agent: {AI-Ccrawlers-Bot-Name-Here}
disallow: /
Blocking OpenAI using the robots.txt file
Add the following four lines to your robots.txt:
User-agent: GPTBot Disallow: / User-agent: ChatGPT-User Disallow: /
Please note that OpenAI has two separate user agents for web crawling and browsing, each with its own CIDR and IP ranges. To configure the firewall rules listed below, you will need a strong understanding of networking concepts and root-level access to Linux. If you lack these skills, consider enlisting the services of a Linux sysadmin to prevent access from the constantly changing IP address ranges. This can become a game of cat and mouse.
#1: The ChatGPT-User is used by plugins in ChatGPT
Here’s a list of the user agents used by OpenAI crawlers and fetchers including CIDR or IP address ranges to block its plugin AI bot that you can use with your web server firewall. You can block the 23.98.142.176/28 using the ufw command or iptables command on your web server. For example, here is a firewall rule to block CIDR or IP range using UFW:
$ sudo ufw deny proto tcp from 23.98.142.176/28 to any port 80
$ sudo ufw deny proto tcp from 23.98.142.176/28 to any port 443
#2: The GPTBot is used by ChatGPT
Here’s a list of the user agents used by OpenAI crawlers and fetchers including CIDR or IP address ranges to block its AI bot that you can use with your web server firewall. Again, you can block those ranges using the ufw command or iptables command. Here is a shell script to block those CIDR ranges:
#!/bin/bash # Purpose: Block OpenAI ChatGPT bot CIDR # Tested on: Debian and Ubuntu Linux # Author: Vivek Gite {https://www.cyberciti.biz} under GPL v2.x+ # ------------------------------------------------------------------ file="/tmp/out.txt.$$" wget -q -O "$file" https://openai.com/gptbot-ranges.txt 2>/dev/null while IFS= read -r cidr do sudo ufw deny proto tcp from $cidr to any port 80 sudo ufw deny proto tcp from $cidr to any port 443 done < "$file" [ -f "$file" ] && rm -f "$file"
Blocking Google AI (Bard and Vertex AI generative APIs)
Add the following two lines to your robots.txt:
User-agent: Google-Extended Disallow: /
For more information, here’s a list of the user agents used by Google crawlers and fetchers. However, Google does not provide CIDR, IP address ranges, or autonomous system information (ASN) to block its AI bot that you can use with your web server firewall.
Blocking commoncrawl (CCBot) using the robots.txt file
Add the following two lines to your robots.txt:
User-agent: CCBot Disallow: /
Although Common Crawl is a non-profit foundation, everyone uses data to train their AI by its bot called CCbot. It is essential to block them, too. However, just like Google, they do not provide CIDR, IP address ranges, or autonomous system information (ASN) to block its AI bot that you can use with your web server firewall.
Blocking Perplexity AI using the robots.txt file
Another service that takes all your content and rewrite it using generative AI. You can block it as follows:
User-agent: PerplexityBot Disallow: /
They also published IP address rages that you can block using your WAF or web server firewall.
Can AI bots ignore my robots.txt file?
Well-established companies such as Google and OpenAI typically adhere to robots.txt protocols. But some poorly designed AI bots will ignore your robots.txt.
Is it possible to block AI bots using AWS or Cloudflare WAF technology?
Cloudflare recently announced that they have introduced a new firewall rule that can block AI bots. However, search engines and other bots can still use your website/blog via its WAF rules. It is crucial to remember that WAF products require a thorough understanding of how bots function and must be implemented carefully. Otherwise, it could result in the blocking of other users as well. Here is how to block AI bots using Cloudflare WAF:
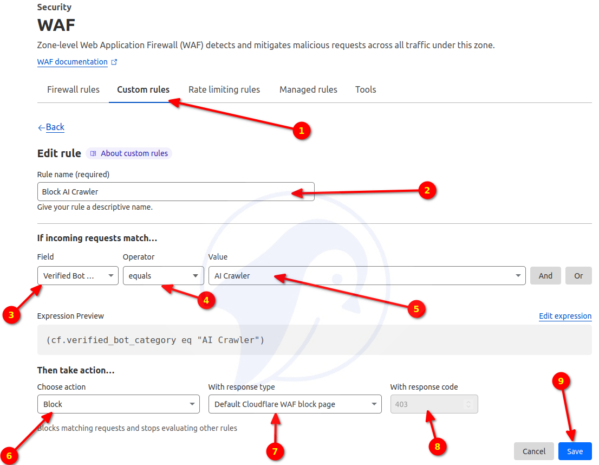
Click to enlarge
Please note that I’m evaluating the Cloudflare solution, but my primary testing shows it blocked at least 3.31% of users. The 3.31% is the CSR (Challenge Solve Rate) rate, i.e., humans who solved the captcha provided by Cloudflare. That is a high CSR rate. I need to do more testing. I will update this blog post when I start using Cloudflare.
Can I block access to my code and documents hosted on GitHub and other cloud-hosting sites?
No. I don’t know if that is possible.
I am concerned about using GitHub, a Microsoft product, and the largest investor in OpenAI. They may use your data to train AI through their ToS updates and other loopholes. It would be best if your company or you hosted the git server independently to prevent your data and code from being used for training. Big companies like Apple and others prohibit the internal use of ChatGPT and similar products because they fear it may lead to code and sensitive data leakage.
Is it ethical to block AI bots for training data when AI is being used for the betterment of humanity?
I have doubts about using OpenAI, Google Bard, Microsoft Bing, or any other AI for the benefit of humanity. It seems like a mere money-making scheme, while generative AI replaces white-collar jobs. However, if you have any information about how my data can be utilized to cure cancer (or similar stuff), please feel free to share it in the comments section.